Red Green Refactor
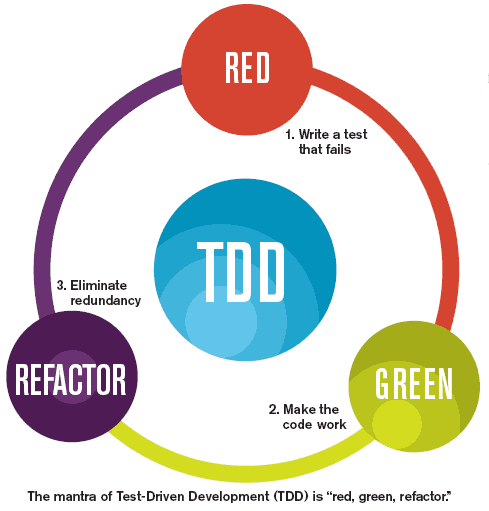
Test-driven development is the practice that involves writing tests before writing the code that is being tested. The test will inevitably fail because no code has yet been written. The developer should watch the test fail, because if it does not fail, it could indicate that some unexpected interaction is affecting your code. After having watched the test fail, you should write the minimum amount of code that will make it pass. Personally, it is this part of the process is, that I found hardest to get my head around, and so I will try to explain it using a simple example.
Let me try to write a software programme that can play the game FizzBuzz. I will use the Ruby testing framework, RSpec to write my unit tests.
The rules of the game are as follows: players count up to a hundred sequentially, each person saying one number. However, there is a catch. If the number is divisible by three, the player must say ‘Fizz’ instead of saying the number. If the number is divisible by five, the player must say ‘Buzz’ instead of saying the number. If the number is divisble by both three and five, the player must say ‘FizzBuzz’.
So where should we start?
First of all, our programme should know whether a number is divisible by three or not. So let’s write a test. In our test we will set an expectation, of what we want to happen when we do something. We could write a test that looks something like this
it 'should know that 3 is divisible by three'
expect(is_divisible_by_three?(3)).to be true
endThis test will inevitably fail, because there is no method ‘is_divisible_by_three?(number)’ yet. At each stage we do the minimum we can. So at this stage, we just want to change the error message that we receive when we run the test. We can go ahead and address the error message telling us there is no such method by creating a method. In Ruby this is done like so:
def is_divisible_by_three?(number)
endThere we have defined our method. But the test will still fail because our expectation was that the boolean value of true would be returned. Instead, we received nil. The next step would be to address this next error message. The simplest code that would make this pass would be to make the method return true. We could write something like this:
def is_divisible_by_three?(number)
true
endThis now makes our test go green. However, this seems counter-intuitive. We know that this method will not actually handle the responsibility that we want it to, it will always return true to us. If we are writing software in a way that is driven by the tests, we will solve our problem by writing our next test, rather than just simply writing the code to handle the responsibility. Good test driven development requires the developer, therefore, to be able to identify the edge cases and the bugs, and write tests to ensure that the programme deals with them correctly.
Our next test could look something like this:
it 'should know that 1 is not divisible by three'
expect(is_divisible_by_three?(1)).to be false
endWe are now forced to update the method is_divisible_by_three?(number) to be able to handle both true and false occurences so that both of the tests will pass.
def is_divisible_by_three?(number)
number % 3 == 0
endThe final stage in the test-driven development framework is refactoring the code. Refactoring is the process of changing the design of the code without changing its external behaviour. A common reason for refactoring can be because of repetition in your code. A prevalent principle in software development is the ‘Don’t Repeat Yourself’ or DRY principle. This principle states that “Every piece of knowledge must have a single, unambiguous, authoritative representation within a system.” If the code is repetitive it can be hard to maintain, and could contain bugs and logical contradictions that will be harder to spot.
In our FizzBuzz programme there will be quite a bit of repetition. We will have three methods that will tell us whether a number is divisible by 3, 5 or 15. You can see how similar they look here:
def is_divisible_by_three?(number)
number % 3 == 0
enddef is_divisible_by_five?(number)
number % 5 == 0
enddef is_divisible_by_fifteen?(number)
number % 15 == 0
endAt this point, we should think about refactoring our code, and extracting the commonalities between these methods into a different method. The only thing that is changing between these three methods is the value of the divisor.
def is_divisible_by?(number, divisor)
number % divisor == 0
endWe could then update each of our methods using our new common method.
def is_divisible_by_three?(number)
is_divisible_by?(number, 3)
endThe refactoring stage is an important one, but one that is all too easy to skip over. As I have discovered, it is massively exciting to get the test to go green, and then there is the urge to move with the flow and get on to writing the next test. One of the challenges that I am trying to undertake as I gain more experience, is to be able to spot where my code needs refactoring, and to clean up my code so that it is more readable and DRY.
The greatest hurdle for tech newbies, at least I found, is that it is incredibly tempting to just write the method the way you think it should be. It can take a lot of brain power to decide where to start with writing the test and it is tempting to be lazy. What I found helpful in overcoming this problem, is thinking of the test as a way of designing the code rather than just being a test to pass. I always ask myself the ‘given, when, then’ questions. Firstly, what is the current state of the programme. Secondly, what is going to occur. Thirdly, when that has occurred, what do I expect to happen. Not all tests will have all of these stages, but asking myself these questions, and writing the test out in psuedo-code has been mighty helpful!
If test-driven development is carried out properly, the design of the programme is emergent rather than planned. This allows for flexibility and clean design but also raises some issues. Firstly, we have to be careful to ensure that we test for all possible edge cases. Secondly, when we test each unit, we create dependencies in our tests that rely on them being a certain structure. For example, say we have created a test that expects a certain object to be an array. If our design emerges in a different path than expected, and guides us to change our data structure a hash instead of an array, some of our tests will break despite the behaviour of the programme not having changed. Problems can arise when we test what an object is rather than what an object does.
Enter behavioural-driven development and acceptance testing. BDD emphasises the behaviour of a system, rather than how it works. The mantra goes something like ‘if it walks like a duck, and talks like a duck, it is a duck’. Our acceptance tests care that it behaves like a duck rather than is a duck. ‘Given’, ‘when’ and ‘then’ are at the heart of the BDD framework, allowing meaningful conversations to take place between clients and developers. Clients understand the behaviour of their product extremely well, even if they wouldn’t know how to build it. The language used by Cucumber, the BDD framework language, gives clients the opportunities to express their desires for the product in a language that is close to English. Once the acceptance tests for one feature are written and are failing, the developer can then drop down into the unit testing to create tests to ensure that the internals of that feature work correctly. The red, green, refactor cycle will still be used to write the code that eventually makes both the unit and acceptance tests pass. This process is known as outside-in development.
To summarise:
- Acceptance testing is all about the behaviour of an object and is carried out first. Watch the acceptance test fail before dropping down into unit testing.
- Unit testing is then used to test and design the internal workings of the system. Write a failing test, make it pass, refactor until the acceptance test passes.
- Repeat the process
Hannah